
Neo4j Write Throughput on Linux ext4 Filesystems
Do you experience poor write performance with Neo4j on your Linux box, especially when it comes to small transactions?
I did, and after some investigations, I could increase write performance by a factor of 15-17x.
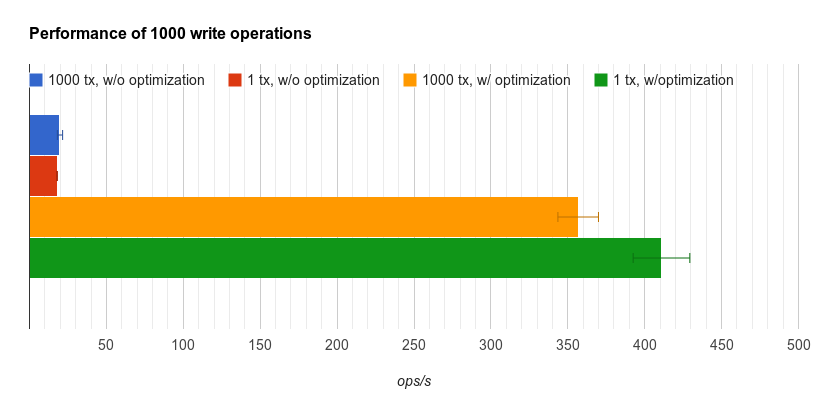
To find out what caused the poor performance I created a test which basically measures the creation of a node, a relationship and some properties.
The system is a standard PC, Core i7 2.93 GHz, 8 GB RAM, Linux kernel 3.8, ext4 filesystem on two partitions, HDDs are ST31500341AS (Seagate Barracuda 1.5 TB 7200.11, SATA II).
Write speed (with disabled write cache) is:
# dd if=/dev/zero of=store bs=1M count=1000
1000+0 records in
1000+0 records out
1048576000 Bytes (1.0 GB) copied, 8.68199 s, 121 MB/s
Profiling the Java app showed that the force() method in the class DirectMappedLogBuffer was consuming most of the execution time.
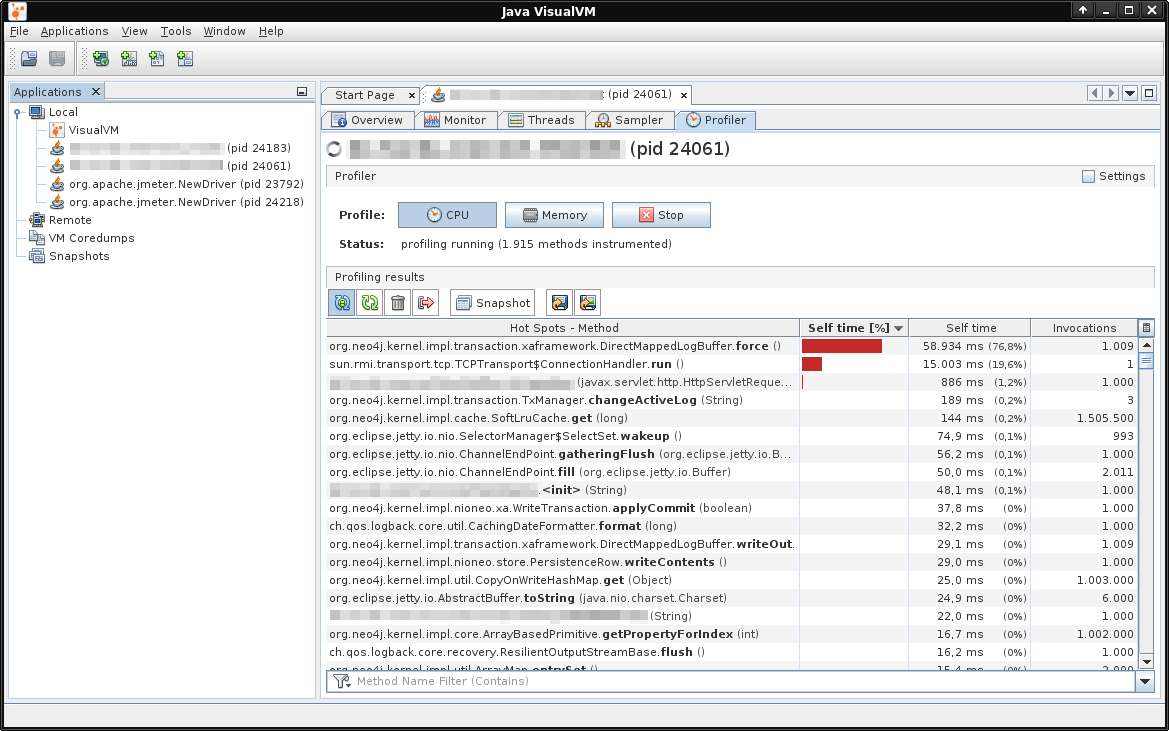
This method is called whenever a Neo4j transaction is committed and something is appended to Neo4j's logical log. In our test, 447 bytes were appended in each transaction.
To ensure that the data is written on physical disk, it calls force() in Java's FileChannel class, which calls fsyncdata() (like fsync() but without changing metadata like time stamp of the file system directory entry).
The first number is for 1,000 single transactions, and the second for one large transaction with 1,000 operations each.
Initial performance
22.62 18.26
19.82 18.25
18.38 17.93
20.22 17.82
18.53 17.84
Median and standard deviation
19.82 17.93
1.71 0.22
That's quite slow, compared to my MacBook which has much better write throughput.
So over the last couple of days, I tried different things to improve write speed.
Disclaimer: Always create a backup of your data before doing anything described here! All changes on your own risk!
Check write cache
In my case, as I have two disk coupled as a software raid array with mdraid, I have to apply these changes to both partitions. A software raid in mode 1 (mirroring) will not significantly cost performance because the changes are written to both disks in parallel.
List partitions of your md array:
mdadm --detail /dev/md0
hdparm -W /dev/sdb1
hdparm -W /dev/sdg1
Check for "write-caching = 1 (on)"
So write cache was initially on, which is default on most Linux systems (I'm using Ubuntu 13.04 here).
Test with write cache off:
20.62 21.00
A tad slower, could have been worse.
Test with write cache on again:
21.76 16.86
That doesn't change anything, strange.
Add noatime mount option
/etc/fstab:
/dev/md0 /data ext4 defaults,noatime 0 2
mount -o remount /data
20.43 19.15
Hm, not really.
So how about journaling?
Journaling options
There's an option called "barrier=0" which is supposed to increase speed:
/dev/md0 /data ext4 defaults,noatime,barrier=0 0 2
Interestingly, this option was default with ext3!
Results:
299.31 347.22
WOW! 15 times faster!
(Note: To disable this performance gain, you have to set barrier=1 and remount again.)
What if we completely disable journaling on the data partition?
Disable journal
You can completely disable journaling on an ext4 filesystem with the following commands. Please make sure you've got a proper backup in place!
# umount /data
# e2fsck /dev/md0
# tune2fs /dev/md0
# e2fsck /dev/md0
# mount /data
Results:
367.78 381.24
Even faster, yeah!
Activate paging options
From http://docs.neo4j.org/chunked/stable/linux-performance-guide.html
Add
vm.dirty_background_ratio = 80
vm.dirty_ratio = 80
Results:
377.07 444.25
Check I/O Scheduler
Make sure to have the noop or deadline scheduler activated on your partitions:
Set filesystem scheduler to noop on /dev/sda:
# echo noop > /sys/block/sda/queue/scheduler
To persist settings, depending on your system, either use sysfsutils and add
block/sda/queue/scheduler = noop
or add a the following option to the kernel command line:
GRUB
kernel /vmlinuz26 root=/dev/sda3 ro elevator=noop
GRUB 2
GRUB_CMDLINE_LINUX="elevator=noop"
Here are the results for the three options:
cfq
61.86 61.84
noop
338.52 363.37
deadline
344.23 441.11
Final results with optimum settings
369.00 402.09
372.02 429.18
357.53 453.72
366.70 411.52
341.76 407.17
369.41 405.52
353.23 389.56
355.62 428.27
330.58 410.34
356.00 429.37
Median and standard deviation:
356.76 410.93
13.19 18.42
Conclusion
The configuraton of a typical ext4 filesystem on a Linux box is probably either not safe, or not as fast as it could be, and can be tweaked for use with Neo4j to make writes up to 17x faster. These numbers are valid for HDD, on an average SSD I reached gains of 5-9x faster.
In case you need 100% transaction safety, and have no battery-buffered disks and controllers, you should actually disable the disk's write cache. You wouldn't even notice much performance loss.
But if you do have battery-buffered disks and controllers, or you don't need 100% transaction safety, you can safely enable write caching (which is on by default), and add barrier=0 to the disk's mount options. In my tests, I observed an impressive 1500% performance boost.
And if you need maximum performance and don't care about safety, disable journaling at all to gain even more write performance.
UPDATE
I'd like to add some feedback from Johan and the Neo4j community (discussion here: https://groups.google.com/forum/#!topic/neo4j/nflUyBsRKyY).
Running on a single-server system without HA with barrier=0 is somewhat dangerous. If you want to ensure data integrity, always go with barrier=1 and also disable the disk's write cache. Even disabling journaling with write caches off can be considered safer.
Changing journaling options on ext4 (such as barrier=0 or disabling it at all) should only be done when you have additional redundancy or a battery-backed system! Running with write barrier=0 in single server mode is not safe and can corrupt data.
Barriers are there for a reason and that is to preserve ordering of writes. If a machine looses power or crashes you may have a transaction that had half of the changes committed to the store files but the data is missing in the log Neo4j uses to guarantee ACID.